روش ایندکس گذاری clustered

در دنیای پایگاههای داده، یکی از چالشهای اساسی، بهینهسازی زمان دسترسی به دادهها است. سرعت بازیابی اطلاعات برای سیستمهای بزرگ و پیچیده اهمیت زیادی دارد و در این راستا، روشهای مختلف ایندکسگذاری به کار گرفته میشود. یکی از این روشها که به طور خاص در پایگاههای داده رابطهای استفاده میشود، ایندکسگذاری clustered است. این روش باعث میشود که دادهها در سطح فیزیکی ذخیرهسازی به گونهای سازماندهی شوند که عملیات جستجو و دسترسی به اطلاعات بهینهتر گردد.
ایندکسگذاری clustered به نوعی است که ترتیب فیزیکی دادهها بر اساس شاخصهایی خاص تغییر میکند. این روش باعث میشود که دادهها با توجه به کلید اصلی، به ترتیب خاصی ذخیره شوند و در نتیجه جستجوهای متوالی روی دادهها سریعتر انجام گیرد. تفاوت این روش با دیگر انواع ایندکسگذاری در این است که ایندکس clustered ساختار اصلی دادهها را تغییر میدهد، در حالی که دیگر روشها فقط یک نمایه اضافی از دادهها ایجاد میکنند.
این تکنیک در مواقعی که نیاز به ذخیرهسازی و جستجوهای سریع در مقیاسهای بزرگ دادهها وجود دارد، بسیار مفید و کاربردی است. بهویژه در پایگاههای دادهای که عملیات خواندن و نوشتن بر روی دادهها به صورت مکرر انجام میشود، ایندکسگذاری clustered میتواند تفاوت قابل توجهی در عملکرد سیستم ایجاد کند. در ادامه، روشهای پیادهسازی و نکات مهم در استفاده از این نوع ایندکسگذاری بررسی خواهد شد.
روشهای ایندکس گذاری در پایگاه داده
ایندکسگذاری یکی از اصلیترین تکنیکهای بهینهسازی پایگاههای داده است که به طور مستقیم بر سرعت دسترسی به دادهها تاثیر میگذارد. بسته به نوع دادهها و نحوه استفاده از آنها، روشهای مختلفی برای ایندکسگذاری وجود دارد که هر یک مزایا و محدودیتهای خاص خود را دارند. این روشها به گونهای طراحی شدهاند که فرآیند جستجو و پردازش دادهها را سریعتر و کارآمدتر کنند.
ایندکسهای clustered
در این نوع ایندکسگذاری، دادهها به صورت فیزیکی در ترتیب خاصی ذخیره میشوند. به عبارت دیگر، ترتیب ذخیرهسازی دادهها مطابق با کلید ایندکس قرار میگیرد. این نوع ایندکسگذاری باعث میشود که دادههای مشابه یا مرتبط به هم در کنار یکدیگر قرار بگیرند و زمان جستجو کاهش یابد.
ایندکسهای non-clustered
ایندکسهای non-clustered ساختاری جداگانه از دادهها دارند. در این روش، دادهها به صورت اصلی در یک ترتیب ذخیره میشوند، اما ایندکس تنها یک نمایه اضافی ایجاد میکند که به سرعت به مکان دادههای واقعی اشاره میکند. این ایندکسها اغلب برای جستجو در ستونهای غیر اصلی دادهها استفاده میشوند.
- مزایا: ایجاد ایندکسهای متعدد برای دادهها، عدم تغییر در ساختار اصلی دادهها.
- محدودیتها: کندی در جستجوهای پیچیدهتر و نیاز به ذخیرهسازی اضافی.
مفهوم ایندکس گذاری clustered
ایندکسگذاری clustered یک روش بهینهسازی برای پایگاههای داده است که هدف آن تسریع دسترسی به دادهها از طریق تغییر ترتیب ذخیرهسازی اطلاعات است. در این روش، ترتیب فیزیکی دادهها بر اساس کلید اصلی ایندکس تغییر میکند، به گونهای که دادهها در کنار هم ذخیره میشوند و این کار باعث کاهش زمان جستجو و دسترسی به اطلاعات میشود. ایندکسگذاری clustered معمولاً برای ستونهایی که به عنوان کلید اصلی انتخاب میشوند، به کار میرود.
در واقع، زمانی که ایندکس clustered ایجاد میشود، دادهها به طور طبیعی به همان ترتیب کلید اصلی ذخیره خواهند شد. این تغییر ترتیب فیزیکی به جستجوها کمک میکند تا سریعتر انجام شوند، زیرا دادهها در کنار هم قرار میگیرند و نیاز به جستجوی طولانی در دیسک کاهش مییابد.
| ویژگیها | ایندکس clustered |
|---|---|
| ترتیب ذخیرهسازی دادهها | تغییر میکند و بر اساس کلید اصلی است |
| تعداد ایندکسها | فقط یک ایندکس clustered برای هر جدول وجود دارد |
| عملکرد جستجو | عملکرد بهتر برای جستجوهای مبتنی بر کلید اصلی |
| فضای ذخیرهسازی | بهینهسازی شده برای جستجو |
تفاوت ایندکس clustered و non-clustered
در هنگام ایندکسگذاری پایگاههای داده، دو روش اصلی برای سازماندهی دادهها وجود دارد که هر یک ویژگیها و کاربردهای خاص خود را دارند. ایندکس clustered و non-clustered از این دو روش هستند که تفاوتهای مهمی در نحوه ذخیرهسازی و دسترسی به دادهها دارند. درک این تفاوتها میتواند به تصمیمگیری درست در انتخاب بهترین روش برای پایگاه داده کمک کند.
ایندکس clustered
در ایندکس clustered، ترتیب فیزیکی دادهها در جدول به طور مستقیم به کلید ایندکس وابسته است. به این معنی که دادهها در پایگاه داده به ترتیب کلید ایندکس مرتب میشوند. این ایندکس تنها یکبار برای هر جدول ایجاد میشود و ساختار دادهها را تغییر میدهد. در نتیجه، جستجوهایی که بر اساس کلید اصلی انجام میشوند، بسیار سریعتر خواهند بود.
ایندکس non-clustered
برخلاف ایندکس clustered، ایندکسهای non-clustered یک نمایه جداگانه از دادهها ایجاد میکنند و ترتیب فیزیکی دادهها را تغییر نمیدهند. این نوع ایندکس فقط یک اشارهگر به مکان دادهها در جدول ایجاد میکند و میتواند چندین بار برای هر جدول ساخته شود. به همین دلیل، جستجوهایی که بر اساس ایندکسهای غیر clustered انجام میشوند، ممکن است کمی کندتر باشند، زیرا باید به مکان واقعی دادهها مراجعه کنند.
مزایای استفاده از ایندکس clustered
استفاده از ایندکس clustered میتواند مزایای قابل توجهی برای عملکرد پایگاه داده به همراه داشته باشد. این روش بهویژه زمانی که نیاز به جستجوهای سریع و بهینه در دادههای بزرگ و پیچیده وجود دارد، به کار میآید. ایندکس clustered به دلیل تغییر ترتیب فیزیکی دادهها و ذخیره آنها بر اساس کلید ایندکس، میتواند در بسیاری از موارد به بهبود عملکرد کمک کند.
افزایش سرعت جستجو
یکی از بزرگترین مزایای استفاده از ایندکس clustered، افزایش چشمگیر سرعت جستجو است. از آنجا که دادهها بر اساس ترتیب ایندکس مرتب میشوند، جستجو در دادههای مرتبط به یکدیگر سریعتر انجام میگیرد. این موضوع بهویژه در زمانی که نیاز به دسترسی سریع به حجم زیادی از دادهها وجود داشته باشد، بسیار مفید است.
کاهش استفاده از منابع سیستم
با استفاده از ایندکس clustered، دادهها به صورت فشرده و مرتب ذخیره میشوند. این امر موجب کاهش تعداد درخواستها به دیسک و کاهش استفاده از منابع سیستم میشود. به همین دلیل، پایگاه داده میتواند بهطور موثرتری عمل کرده و پاسخدهی سریعتری داشته باشد.
نحوه ایجاد ایندکس clustered در SQL
ایجاد ایندکس clustered در SQL یکی از مراحل کلیدی برای بهینهسازی پایگاه داده است. این فرآیند نیازمند انتخاب ستون مناسب برای کلید اصلی است که بر اساس آن دادهها مرتب و ذخیره میشوند. ایجاد این نوع ایندکس باید با دقت انجام شود زیرا تأثیر زیادی بر روی ساختار پایگاه داده و عملکرد آن دارد. برای ایجاد ایندکس clustered در SQL، باید از دستورات خاصی استفاده کرد که ساختار دادهها را تغییر میدهد.
ایجاد ایندکس clustered هنگام ایجاد جدول
در هنگام ایجاد جدول جدید، میتوان ایندکس clustered را بهطور خودکار برای ستون کلید اصلی (primary key) تعریف کرد. به طور معمول، SQL این ایندکس را بهطور پیشفرض برای ستون کلید اصلی ایجاد میکند. دستور زیر نمونهای از نحوه ایجاد جدول همراه با ایندکس clustered است:
CREATE TABLE Employees ( EmployeeID INT PRIMARY KEY, Name NVARCHAR(100), Position NVARCHAR(100) );
ایجاد ایندکس clustered برای یک ستون خاص
اگر بخواهید ایندکس clustered را برای یک ستون خاص بهجز کلید اصلی ایجاد کنید، میتوانید از دستور CREATE CLUSTERED INDEX استفاده کنید. در اینجا، میتوانید ستونهایی را انتخاب کنید که برای مرتبسازی دادهها مناسب هستند:
CREATE CLUSTERED INDEX IDX_EmployeeID ON Employees (EmployeeID);
تاثیر ایندکس clustered بر عملکرد جستجو
ایندکسگذاری clustered تاثیر زیادی بر عملکرد جستجو در پایگاههای داده دارد. این نوع ایندکس با تغییر ترتیب فیزیکی دادهها بر اساس کلید ایندکس، امکان دسترسی سریعتر به اطلاعات را فراهم میآورد. زمانی که دادهها بر اساس ایندکس clustered سازماندهی میشوند، جستجوها به خصوص برای دادههای مرتبط یا متوالی بسیار سریعتر انجام میشوند. این ویژگی بهویژه در پایگاههای داده بزرگ و پیچیده که نیاز به جستجوهای مکرر دارند، اهمیت زیادی دارد.
یکی از اثرات اصلی ایندکس clustered بر عملکرد جستجو این است که زمان بازیابی دادهها کاهش مییابد. به دلیل اینکه دادهها به ترتیب مرتب ذخیره میشوند، فرآیند جستجو نیازی به جستجوی طولانی در بخشهای مختلف پایگاه داده ندارد. علاوه بر این، عملیاتهایی مانند مرتبسازی و فیلتر کردن دادهها نیز با ایندکس clustered سریعتر انجام میشوند، زیرا دادهها از قبل به شکل بهینه ذخیره شدهاند.
محدودیتها و چالشهای ایندکس clustered
هرچند ایندکسگذاری clustered مزایای زیادی در بهینهسازی عملکرد جستجو دارد، اما این روش محدودیتها و چالشهایی نیز به همراه دارد. از آنجا که ایندکس clustered مستقیماً بر ترتیب فیزیکی دادهها تأثیر میگذارد، تغییرات در ساختار پایگاه داده و نگهداری آن ممکن است مشکلاتی را ایجاد کند. این چالشها ممکن است بر عملکرد سیستم در شرایط خاص تأثیر بگذارند.
محدودیتهای ایندکس clustered
- فقط یک ایندکس clustered برای هر جدول قابل ایجاد است. این محدودیت میتواند در صورتی که نیاز به ایندکسهای متعدد با ترتیبهای مختلف باشد، مشکلساز شود.
- ایجاد و نگهداری ایندکس clustered ممکن است بر عملکرد درج، بهروزرسانی و حذف دادهها تأثیر منفی بگذارد. زیرا تغییر در دادهها ممکن است نیاز به تغییرات در ترتیب فیزیکی دادهها داشته باشد.
- اگر دادهها به طور مکرر تغییر کنند، ایندکس clustered ممکن است دچار مشکلاتی در سازگاری با دادهها شود و در نتیجه کارایی کاهش یابد.
چالشهای استفاده از ایندکس clustered
- زمانی که دادهها به تعداد زیادی تقسیم میشوند یا حجم پایگاه داده بسیار بزرگ است، مدیریت ایندکس clustered میتواند پیچیدهتر شود.
- در سیستمهایی که نیاز به دسترسی سریع به دادهها از طریق ستونهای مختلف دارند، استفاده از ایندکس clustered ممکن است کارآمد نباشد و به جای آن ایندکس non-clustered مناسبتر باشد.
ایندکس clustered و ترتیب دادهها
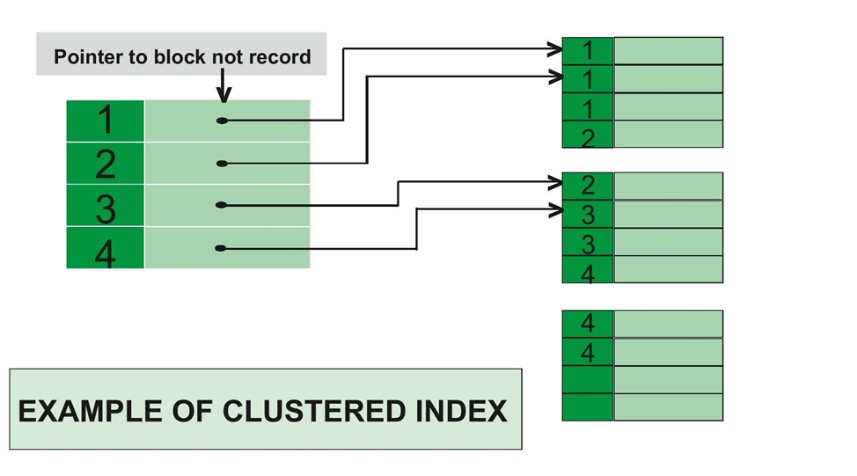
یکی از ویژگیهای برجسته ایندکس clustered این است که ترتیب فیزیکی دادهها را در پایگاه داده تغییر میدهد. این تغییر ترتیب بر اساس کلید ایندکس انجام میشود و در نتیجه دادهها به شکلی ذخیره میشوند که دسترسی به آنها سریعتر و کارآمدتر گردد. در این فرآیند، دادهها بر اساس مقادیر کلید ایندکس به صورت پیوسته و مرتب ذخیره میشوند، که باعث بهبود عملکرد جستجوهای مبتنی بر این کلید میشود. این نوع ایندکس به ویژه زمانی که عملیات جستجو یا مرتبسازی بر اساس یک ستون خاص انجام میشود، کاربرد دارد.
ترتیب دادهها به این صورت که با ایندکس clustered تغییر میکند، نه تنها برای جستجوهای سریعتر مفید است، بلکه بر روی عملیاتهایی مانند ادغام دادهها (merge) و بهروزرسانیها نیز تأثیر مثبت دارد. این ویژگی به مدیریت و دسترسی به دادههای مربوطه در هنگام انجام تراکنشها کمک میکند.
| ویژگی | تأثیر بر ترتیب دادهها |
|---|---|
| ایندکس clustered | ترتیب دادهها بر اساس کلید ایندکس تغییر میکند و دادهها در کنار هم ذخیره میشوند. |
| ترتیب فیزیکی دادهها | دادهها به صورت مرتب و متوالی بر اساس مقادیر کلید اصلی ذخیره میشوند. |
| جستجو | سرعت جستجو برای دادههایی که به ترتیب ذخیره شدهاند، افزایش مییابد. |
یک پاسخ بگذارید
دسته بندی
- چگونه در بورس سود کنیم
- تحلیل تکنیکال
- تحلیل بین بازاری فارکس
- تجارت الگوریتمی
- استراتژی های معاملاتی
- پلتفرم معاملاتی فارکس
- دوره جامع بورس
- منصة التداول الأكثر ثقة
- ابزارهای معاملاتی
- فارکس حرفه ای در افغانستان
- بروکرهای پیشنهادی
- الفوركس للمبتدئين
- ویدئوهای آموزشی فارکس
- سکوهای تجاری سفارشی
- معاملات با Forex
- کتاب آموزش بورس